
On July 18th, 2020, a configuration error in Cloudflare’s backbone network caused an outage for about 27 minutes affecting businesses worldwide.
The error configuration sent all traffic across the backbone to Cloudflare’s Atlanta node and unfortunately “overwhelmed” the router. Cloudflare later mentioned they saw traffic drop by about 50% across the network.
Although not entirely catastrophic thanks to the architecture design, but many locations with heavy internet usage were affected including San Jose, Seattle, Los Angeles, Chicago, Washington, DC, London, Amsterdam, Frankfurt, Paris, Stockholm, Moscow, São Paulo, and the list goes on.
How our system handled it
Cloudflare is one of the many CDNs Mlytics offer via Power-Ups (CDN marketplace) on the platform. When the outage occurred, the Smart Load Balancing swapped out Cloudflare with the next best-performing CDN (varies in different regions) for requests.
The chart below is the Smart Load Balancing optimization chart, it shows which CDNs were used (swapped over) during a certain timeframe. In this case, we’re using a demo site with Akamai and Cloudflare installed. As shown, Akamai had several query spikes in the states due to the Cloudflare performance drop – the system is actively swapping over to Akamai.
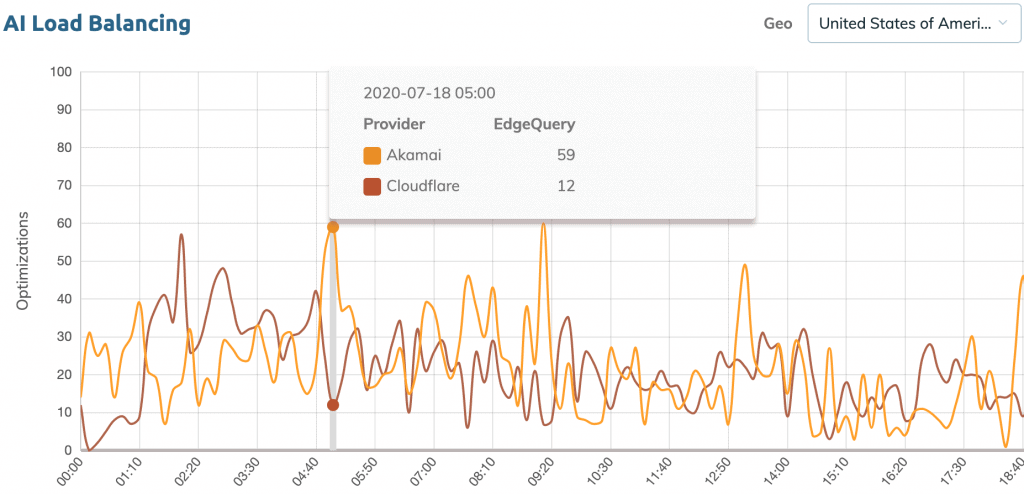
This had successfully helped many of our customers mitigated the outage, and we received no complaints over the course.
On the Pulse chart, we’re also seeing a latency spike and availability drop for Cloudflare in the same time frame. This helps illustrate a clear picture of what happened when aligning this with the chart above.
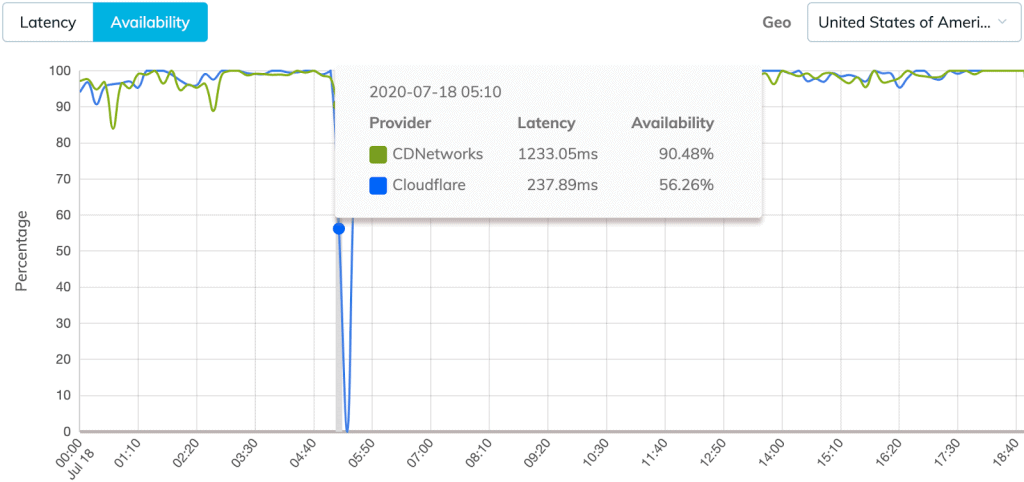
We believe all the CDN providers are doing their best to deliver the best performance possible, but unfortunately, things do happen. And our job at Mlytics is to help our customers minimize the exposure of such risk and maximize the uptime at all times.
Again, outages DO happen
This is a wake-up call reminding all businesses will eventually have to deal with outages if offering any form of web services. Thus, a solid cloud redundancy and disaster recovery plan in place to prevent any event from taking down your service is imperative.
Imagine losing money and customers hate you… horrible right? But stopping users from doing what they were doing (especially if they enjoy it so much) is your express train ticket to PR hell.
Small or medium businesses might have room for mistakes, but some of the bigger companies affected by the outage such as Discord, Feedly, Politico, Shopify, and League of Legends might not be so lucky. These are some of the most used online services today, and imagine millions of users got disconnected without being informed.
We talked about website downtime causes and solutions in the past, and there are just so many factors that can bring a website off the grid. A website without a backup plan is exactly like sailing a cruise without liferafts – you’re betting you won’t need it.


")